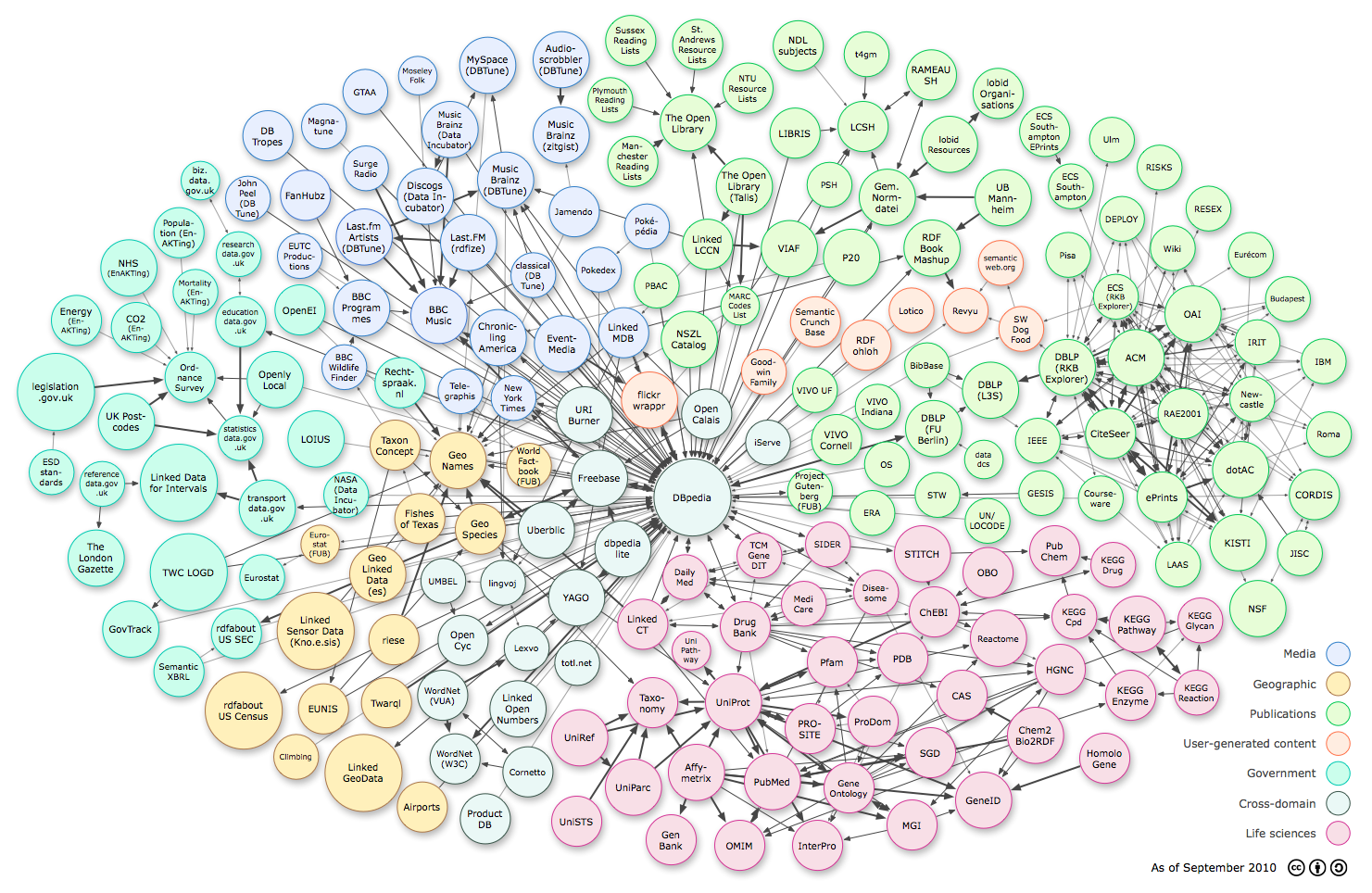
 In the digital age, "my data" is increasingly becoming "my self". The diagram on the left (attribution) shows the datasets that have been published in Linked Data format, "a recommended best practice for exposing, sharing, and connecting pieces of data, information, and knowledge on the Semantic Web using URIs and RDF" (Wikipedia). Among others, they include a lot of media, government and user-generated content but, despite the apparent complexity, they form arguably a very small percentage of the archives and databases that are NOT exposable, shareable and connectable.
In the digital age, "my data" is increasingly becoming "my self". The diagram on the left (attribution) shows the datasets that have been published in Linked Data format, "a recommended best practice for exposing, sharing, and connecting pieces of data, information, and knowledge on the Semantic Web using URIs and RDF" (Wikipedia). Among others, they include a lot of media, government and user-generated content but, despite the apparent complexity, they form arguably a very small percentage of the archives and databases that are NOT exposable, shareable and connectable. Most frequently, a significant part of our lives is recorded and stored somewhere in digital form. Our documents, e-mail messages, pictures and videos, both at work and at home, are increasingly being stored on networked disks or in the cloud. But a lot more data, including structured data, is contained inside a growing number of archives and databases, both private and public, more or less accessible and even unknown to us. Defining and regulating data ownership and data access are becoming key issues of our contemporary age.
Let us examine in more detail the breadth and depth of this data space. Let us try to compare the number of personal letters that a typical individual might have been storing at home in the past decades, including all correspondance with public offices, with the number of messages that are stored in our e-mail accounts. Or the amount of information concerning their citizens that our governments have ever been able to accumulate on paper with the amount of digital data of the same kind. Then let us try to imagine how many data had never been stored in any form before the web: bookmarks, rfid data, photos, videos, blogs, social network interactions, telecommunication-related data. It is uncomfortable even just to enumerate the first categories that come to mind: there are plenty of them !
As the Internet gets bigger and deeper, everyone is encouraged to share more and more data through a number of bloating data repositories like Wikipedia, Youtube, Freesounds or Facebook. Data visibility is strictly related to the number of links between them, as every blogger knows. But, unlike the average blog, many data repository are perfectly sealed: you may not even access your own data. Most governments are particularly proficient in this activity.
No comments:
Post a Comment